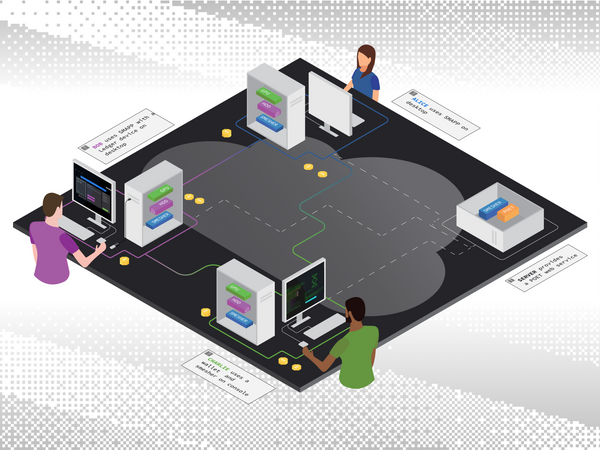
This 3-part blog post is intended for a technical audience who would like to understand the Spacemesh consensus protocol. It includes the motivation for the protocol and provides a high level informal protocol overview. This post is the first of a series of technical blog posts we are going to publish about various technical aspects of Spacemesh and is mostly based on Tal Moran’s presentation in SF Blockchain week 2018. If you prefer watching a video to reading, then please watch this https://youtu.be/jvtHFOlA1GI . Shoutout to Tal Moran, Barak Shani, Liat Hoffman and other Spacemesh family members for providing invaluable insights and edits to this post.
Part I - Background
What’s inside a cryptocurrency?
The two most critical parts of a cryptocurrency are the consensus mechanisms and the incentive mechanisms.
One can think of a cryptocurrency as a kind of distributed state machine, where the state essentially consists of which accounts hold all the coin in the system, and there are pre-agreed upon rules about how this state can evolve (e.g. coins can go from one account to another, but not appear out of thin air).
For such a state machine to work as a cryptocurrency, it is critical that there is consensus on the current state, and that the state evolves only according to the rules. In all existing cryptocurrencies, we achieve this by constructing a distributed ledger: this is basically a record of all state transitions (in the case of a currency, a state transition is a transaction), starting from a pre-agreed upon initial state (i.e., “Genesis”). This ledger must satisfy two properties:
(i) Consensus: everybody agrees on the current state (ii) Irreversibility: history cannot change (i.e., transactions can be appended to the ledger, but not removed or changed). For example, if everyone agrees today that Alice paid Bob last week and both of their accounts balances changed, then tomorrow everyone will still agree that this happened Alice’s payment to Bob can’t be “reverted”.
Another important property is the incentive mechanism. Running a cryptocurrency protocol has costs such as computation, storage and networking, and if we want people to run a cryptocurrency honestly/ according the rules then we need to give them an incentive to do so.
Distributed Consensus is Hard
Consensus is a classic “hard problem” in distributed computing. It has been studied for over 30 years, well before the blockchain era, and is still actively being studied today. The main challenge is knowing who to trust. There are lots of parties that need to agree, but we don’t know which of them are honest. Some might be acting maliciously, and because we don’t know who is honest, it is hard to decide who to listen to and who not to listen to.
The Sybil Problem
Permissionless consensus where we don’t have fixed identities is impossible. The reason is that an adversary can create unlimited identities, duplicating himself as many times as he wants. This is called the Sybil problem. In fact, it was shown in the 80’s via a mathematical proof that consensus is impossible without an honest majority. Since adversaries can duplicate themselves as many times as they wish to Sybil identities, there can be no honest majority in permissionless settings.
From People to Resources
Bitcoin’s breakthrough was to change the model. Let’s replace identities we can’t verify with computational work. Computational work has some nice properties. It is very easy to measure a proof of work and hard to fake one. It is easy to independently measure how much work was done on a simple stand-alone proof and it is also hard to fake, under fairly reasonable cryptographic assumptions. One can’t prove he’s done the work without actually doing the work. Because computational power is an expensive limited resource, proof of work solves the sybil problem. One does not benefit from creating many identities because we measure CPU power and not the amount of identities. So instead of assuming that the majority of participants is honest, we assume that the majority of CPU power is controlled by honest parties. With this new assumption we sidestep the impossibility result of permissionless consensus with costless entities.
From Resources to Consensus
To create a cryptocurrency consensus with proof of computational work, we elect a leader by lottery. All parties in the system compete in a race to solve a computational puzzle. The party that solves the puzzle first is elected as leader and determines the next block of transactions that should be added to the cryptocurrency state. In this probabilistic model, all parties participate in a computational race and need to perform computational work as fast as possible. The parameters and difficulty are chosen so most of the time everyone agrees on a single leader. We reach consensus on how to update the state by agreeing to update the history with the single leader’s provided block. This works but the problem is that we may have disagreements when two or more leaders are elected in close proximity. Because the model is probabilistic, sometimes more than one entity solves the proof of work puzzle at approximately at the same time. Because we can only have one leader, all the computational work performed to create blocks by all other parties will be discarded and we agree on one leader based on blocks content.
The Problems with Races
The first problem is that races are time sensitive. This means that we have a high competitive costs for large blocks. I care how fast I can get my block to all other parties. The larger the block, the longer it takes to transmit it to everybody else, and the more likely I am to lose the race compared to someone who created a smaller block that reaches everybody else more quickly. The block size limitation is a problem because it constrains the cryptocurrency transaction throughput.
The second problem is that races lead to perverse incentives. In some cases, it is better to withhold blocks instead of immediately sending them to everyone, and to publish them at a later time in order to get more rewards. However, if everyone acted in this way, the security of the system would break down.
And finally, we have a problem of unfair reward distribution. For example, if I create a block by solving the proof of work puzzle, I know its content before I transmit it and so before everybody else does. In this case, I get a head start on the race to generate the next block compared to everybody else. This means that the more computational power I have, the more unfair share of rewards I can get because I’m getting a head start on other entities with less computational power.
The Downside of Proof of Work
So we explained why races do not lead to optimal results. Proof of work by themselves are also problematic. First, computational power is an expensive limited resource: not only in terms of monetary cost, but also environmental cost. Bitcoin currently consumes as much power as a medium-sized country. This means a lot of carbon in the air and all of the unfortunate consequences that follow from the global warming this carbon footprint causes. Unfortunately, the high cost is inherent to proof of work. It is not something we can get around, because the honest miners must use as much power as they can, otherwise the honest majority of computing power can be violated, and the network undermined. The honest miners can’t work less because the core assumption is that they create an honest majority. If they work less, they won’t keep up with the adversaries who work as hard as they can and this would lead to a violation of the honest majority assumption. Finally, because it is so expensive in monetary terms, we get higher transaction costs because we must reimburse miners to ensure they participate. In a cryptocurrency steady state, we need to reimburse miners with transaction fees.
Part II - Spacemesh Consensus Protocol Motivation
Motivation
First, we want to replace proof of work with another, more environmentally-friendly resource.
Second, we want to remove the leader-election requirement and avoid races. This will allow us to have a fairer reward distribution, which is linear to the amount of resources you have, and will allow us to substantially increase the transaction throughout because we can accept more blocks at the same time rather than just one block. Getting rid of races creates the very nice property of “incentive compatibility,” which means that we’ll be able to prove that if the consensus is race-free, then it is more rational to follow the protocol and publish new blocks immediately. The way we define “race-free” is that no matter what anybody else does, the honest majority will get their reward. So for example, by not publishing a block, we can at worst only cause ourselves to lose rewards and not impact another honest participant’s rewards.
Finally, we want a consensus protocol that we can formally analyze and prove to be secure. The only way to get real confidence that our cryptocurrency is secure, is to have some kind of formal proof that reduces the attack surface to a set of well-studied conservative cryptographic assumptions. Once we do this, we can ensure that if you can attack the cryptocurrency then you can attack lots of other things that many cryptographers have studied for a long time, and are widely accepted as secure, rather than claiming that we just don’t know how to attack the protocol. In other words, as long as the underlying cryptographic primitives remain secure, so too is our protocol.
Alternatives to Proof of Work
So, what is a good alternative to proof of work? Using money has been suggested instead of computation. So, instead of proving computational work, we prove possession of funds. This methodology, known as proof of stake, is cheap in terms of cost per miner because we only require signatures. A second option, which is what Spacemesh is using, is proof of space-time. By this we mean keeping portion of your disk full for a specified period of time. Proof of space-time is the correct definition we need for a cryptocurrency. Proofs of space-time are much cheaper then proofs of work because storing data is much cheaper than performing constant computation using a CPU and they are much cheaper in terms of environmental costs, because the energy used is significantly lower. They are not quite as cheap as proofs of stake but this is actually an advantage, as I will now explain.
Issues with Proof of Stake
First, proofs of stake are very cheap. There’s nothing that prevents a cartel of several parties that owned a lot of stake at some point in time in the past and possibly have already been sold, to collude and generate an alternative history that will reverse the current state. This requires additional security assumptions which might be non-standard.
Second, proof of stake cryptocurrencies are not quite permissionless. One can’t just join the system at will without someone else’s permission as one needs to buy stake from the owners of the current stake. The stake owners must agree to sell the stake which is a permission to join the network. Some proof of stake cryptocurrencies require a high minimum stake to participate, which makes them prohibitively expensive for poor entities to join the system. In other words, entities that would like to join the system may not be able to afford the minimum high capital needed to do so. Both of these issues decrease the decentralization of such systems which in turn negatively impacts security, as the less decentralized a system is, the easier it is for miners to collude and attack it. This type of proof is the economic status quo from my perspective - that is, the world already works this way. It does not fulfil the promise of the blockchain, namely: a permissionless, trustless and decentralized economy.
Part III - The Spacemesh Consensus Protocol
First some preliminaries. We divide time into fixed length units we call layers. This is a similar concept to Bitcoin’s 10 minute ideal block generation time. Next, we set a lottery to pick block generators for each upcoming layer. We assume that all parties have the same clock time up to a bounded time shift and set the layer time to account for such drifts in parties’ clocks.
A party is eligible to submit a block in a specific layer only if it has a valid proof of space-time allocated - that is, a certain amount of disk space set aside for a certain amount of time for use on the Spacemesh network. We uniformly sample the eligible parties with a fixed sample size, for example 200 parties per layer. These ‘winning’ parties can submit blocks to that layer and so the protocol acknowledges all valid blocks from these parties.
Unlike blockchain-based protocols that only pick one block per layer such as Bitcoin or Ethereum, we choose many blocks per layer as long as the blocks have a valid structure and were submitted by entitled parties for that layer.
Consensus is achieved by everybody agreeing on total ordering of blocks. To achieve this, we first order blocks by layer number, so all blocks in layer 1 are before all blocks in layer 2, and next we sort blocks within a layer by the block’s content hash.
This ordering is necessary but insufficient for achieving consensus. The problem is that honest parties don’t always agree on the exact time of each block. In a p2p internet network, different parties see blocks submitted by other parties at different times due to variable network latency. So, some parties may receive a block that claims to be in a specific layer too early or too late, meaning closer to the layer start or end time.
Accepting blocks that we received too late is the main technical difficulty for achieving consensus for the following reason. Assume we accept blocks to a layer that ended a long time ago. This reverses history and prevents us from getting the irreversible history property that we want. So we definitely can’t accept a block that was received a lot of time after the layer ended and there must be a cutoff point after which we reject blocks that claim to belong to a given layer. So what happens when one party gets a block right before the cutoff time and one right after? A common use case in an asynchronous p2p network.
The basic idea is that we are going to use votes. Conceptually, every block votes on the validity of all previous blocks and we count votes to decide on validity. In practice we use several optimization techniques to make this voting process practical to run.
So, for a block in question, we are going to count votes and let the majority decide on validity - that is, should it be included in its claimed layer or get disregarded. Since we randomly sampled the parties that submit blocks from the total space allocated to Spacemesh, and we assume that the majority of total space allocated belongs to honest parties, the majority of blocks in any layer is generated honestly with a very high probability.
If all the honest blocks (blocks submitted by honest parties) vote the same way, we reach consensus. As the number of new honest blocks exceeds new dishonest blocks, and as all honest blocks vote the same way, the number of votes on each valid block becomes larger and larger over time, and it becomes impossible to reverse the voting decision on the validity of a block. We call this protocol the Tortoise because it is slow and steady but guarantees eventual irreversibility.
However, this is not enough. What is described above gives us irreversible consensus after enough votes have been cast, so for example, we may reach consensus quickly regarding the previous layer of blocks, but the honest parties might not agree on new blocks.
This is why we also need the Hare protocol. It is basically a Byzantine fault tolerant agreement algorithm that we run on recent blocks. This construction is modular in the sense that we can choose different Hare protocol parameters for different security / efficiency tradeoffs.
So to summarize, if we look at the timeline, the Hare protocol is used to achieve consensus on recent blocks and all honest parties will use these results to decide which new blocks are valid, and for older layers we use the Tortoise protocol to count votes and reach consensus on irreversible history.
From Block Order to Cryptocurrency
So I described above how we intend to get a total order on blocks, but for a cryptocurrency we also care about the total ordering of transactions. The nice thing about total ordering of blocks is that it also gives us the total ordering on transactions. We solve this in a similar way to how we order blocks in layers. First, we say that a transaction is before another transaction if it is in a block that is before the other transaction’s block. Secondly, we order transactions within a block by their hash. On the consensus layer we don’t care about the semantics of the transactions, i.e. how they attempt to change the global state, and care only about their syntax, i.e. the correctness of their data format. The transactions are processed by another higher-level component to evolve the cryptocurrency state. In that component we discard invalid or duplicated transactions.
Proof of Space-Time Challenges
There are some new challenges we address that are created when we switch from proof of work to proof of space-time consensus mechanisms. In a proof of work based blockchain, one can think of a block at a specific point on the chain as “voting for’’ the entire history from that point (and voting against any blocks that exist from that point onward). Since each computational effort is bound to a single block, it is also bound to a single vote. In addition, the proof is a mandatory part of a submitted block, and it is easy and efficient to verify that the work was performed.
In proof of space-time, we do not wish to bind the stored data to a single vote. The reason is that we want a system where users allocate data once and do not change it all the time. If we need to change it all the time then it means that we are doing computational work which is exactly what we want to avoid.
We want to add different votes over time, but we don’t want to have to replace the stored data. What we’d like to achieve is to use the same effort multiple times for many votes without modifying our storage. This creates a Nothing at Stake problem which also exists in proof of stake based consensus mechanisms.
Secondly, proof of work is self-certifying and non-interactive. If I look at a proof of work, I can validate that somebody did the work to generate that proof without any additional information. In proof of space-time, we need to prove that I stored data for a period of time, say one week, but the problem is that time is subjective. A proof of space-time has two parts. The first part is how much data is stored, and the second part is for how long it has been stored. However, the point in time at which I started storing the data is not an inherent part of the proof. For example, say I received a proof of space-time a week ago and I validate it, now I know that storage was allocated a week ago. However, a week later (today) I wish to validate the cryptocurrency history from genesis to the current state, I won't know which proofs were valid because I just received them now and not at their claimed time. This creates a problem called costless history extension where I create proofs regarding things in the far past although I only started working a week ago.
Dealing with Nothing at Stake
To deal with the “nothing at stake” problem, we bind space allocated to a specific ID. This makes creating new IDs costly because allocating space costs computation work. By the honest majority assumption, an adversary can’t create too many identities. So, some computational work needs to be done to create an identity. Secondly, reuse of an ID for two different votes is easily detected and the votes get cancelled.
It is important to note that punishments such as slashing, which are necessary with a proof of stake based system to solve the “nothing at stake” problem, are not necessary in the Spacemesh network for security. Canceling bad votes is needed to defend against the worst case behavior as a last resort.
We only need to rely on the honest majority of storage. Canceling out the old votes of adversaries doesn’t change the irreversible status of old blocks, because there are more honest votes than sybil votes. We prove the security without having to create a punishment for bad behavior.
Dealing with Costless History Extension
We combine proof of elapsed-time (PoET) with proof of space-time (PoST) to create non-interactive proof of space-time (NIPST). The core idea is that we use the PoST commitment as a challenge to a PoET service and use the proof of elapsed time as a challenge to the PoST to create a NIPST. So what we get is a self-contained (non-interactive) proof that proves that (i) we allocated a specific amount of space at the PoET service wall start time and (ii) we are still allocating that space after the PoET configured duration, for example 2 weeks. These proofs are published by parties on the mesh to claim eligibility to submit blocks to the system.
Self Healing
An important feature of the Spacemesh protocol is what we call Self Healing. It is important for a cryptocurrency that is designed to secure a ledger of a large amount of value to be able to recover from a temporary violation of assumptions. In a probabilistic security proof, despite the probability of bad things happening being so infinitesimal, they can still happen (if seldom). At Spacemesh, we assume an honest majority of parties is sampled for the Hare protocol. The probability of the sampled parties not having an honest majority is very small, but over many years of the protocol running, this event may occur. What we need to ensure is that consensus does not fail even when this assumption breaks. Without Self Healing, every violation of the assumption may break consensus in a way that is unrecoverable. For example, in a proof of stake system, if a select committee of stakeholders doesn’t have an honest majority then the whole system may break down which is a bad thing.
To recover from such a rare event, we use an extra ingredient in the protocol: a common public coin. This is an idea taken from traditional Byzantine agreement research. We establish a common public coin at the beginning of every layer and we modify the Tortoise voting rule for old blocks to consider the common coin. When we sum the votes for a block, if there is no large margin of votes in favor of including the block in a layer, then we consider the public coin and all honest parties will agree on the vote.
Summary
You made it all the way here! I hope that you now have a general idea of our motivation and how the protocol generally works. There are many important protocol details that I didn’t cover here such as Tortoise optimizations, Tortoise and Hare committees sampling, Hare protocol constructions and the incentives structures. I will cover that in future blog posts, so watch this space. The full specifications of the protocol and the security proofs are in the works and are going to be published in an (IACR) eprint. Subscribe to our email updates to receive a notification when the protocol spec is published, and click here to sign up to participate in our upcoming testnet to see it all in action.